22 Top Open source Text To Speech Software

Text-to-speech (TTS) software has the capacity to process and read content aloud.
In most cases, artificial intelligence (AI) is used. However, these software do not comprehend the text at hand.
They know how to pronounce the words. Excellent text-to-speech software comes with a wide range of voices that match the users’ needs.
These tools are essential if you intend to create easily accessible content, proofread written text or add natural-sounding voice-overs to videos.
Word processors such as Google Docs and Ms Word have a simple built-in TTS feature that read text aloud. The results generated are typically accurate owing to significant updates.
Nonetheless, these lightweight TTS readers cannot match fully featured text-to-speech software. Mark you; some do not have the option to download audio files. This makes them less efficient if you are working on projects such as creating videos for YouTube and social media platforms.
In case you are having a hard time in choosing the best open source TTS software, do not fret. We have compiled 22 best software to get you unstuck.
OpenTTS
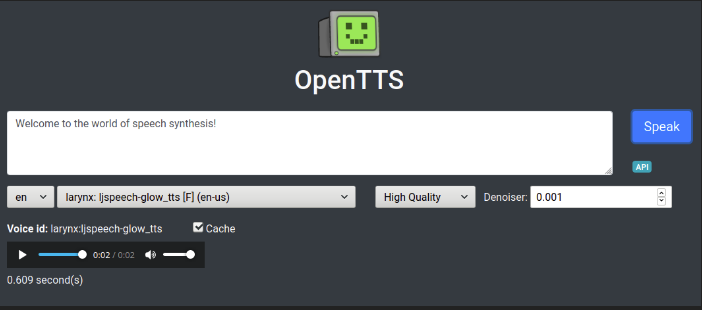
This is a free to use open-source TTS software. OpenTTS is written in Python and licensed by MIT.
Features;
- It supports many languages.
- Has diverse alternative libraries.
- It avails every text to speech engine via one HTTP API.
- OpenTTS can be used without custom plugins because there is a MaryTTS-compatible HTTP API.
- It can mix various voices with customized word breaks and pronunciation.
Pros;
- Comes with a permissive license.
- There are no reported vulnerabilities now.
- It has a build file.
- Its code complexity is ranked at medium.
Cons;
- Installation instructions are not easily available.
MaryTTS
This open-source TTS software is Java-based.
Features;
- It is multilingual.
- MaryTTS has a modular architecture.
- Unit selection synthesis alongside prosody modelling for audio customization.
Pros;
- It is popular and receives support from the developer community.
- MaryTTS can be easily integrated with other platforms.
- The software generates natural sounding audios.
Cons;
- Some users might find it difficult to access its documentation.
- The quality of voice depends on the language.
- It requires extensive computational resources for large texts.
PicoTTS

This is a lightweight, android open-source TTS software.
Features;
- It is lightweight making it suitable for low-performance devices.
- The user can customize pronunciation of different vocabularies.
- Multilingual support.
Pros;
- It is compatible with android devices.
- PicoTTS can be integrated with other platforms seamlessly.
- This software requires few resources to run.
Cons;
- Compared to other software on the list, PicoTTS lags behind in terms of quality.
- It has few voice options.
- It lacks advanced customization options.
eSpeak

eSpeak is a simple TTS software. It is popular because using it is easy.
Features;
- It is compatible with operating systems like android, Windows, Linux, and Mac.
- The user can customize the pitch, volume, and speed.
- Multilingual support.
- It can produce speech in a WAV file format.
- Its written in C.
Pros;
- It generates clear and audible audio files.
- Using the software is easy even for beginners.
- eSpeak is compact and takes up less space on devices.
Cons;
- It does not have adequate advanced features due to its lightweight nature.
- The voice quality does not cut across all languages.
Athena

An open-source TTS software, which is sequence-to-sequence, based.
Features;
- Quick speech generation.
- It has multi-GPU training for multiple devices.
- Creation and decoding is WFST based
- Tensorflow C++ deployment.
Pros;
- It is suitable for industrial and academic research purposes.
- Multilingual.
- It can spot keyword.
- Unsupervised pre-training.
Cons;
- The software is complex.
Mimic 1

This is a text-to-speech engine that is based on FLITE software.
Features;
- Works well on Android, Linux and Windows.
- It has numerous high quality voices.
- Mimic 1 is resource effective.
- Low-latency.
Pros;
- Consistent advancements and upgrades.
- Natural sounding voice generation.
- It supports many languages.
- It is easy to use.
Cons;
- None.
RHVoice

An open-source TTS system can generate speech from text.
Features;
- Its resources are language specific to improve accuracy.
- RHVoice has a hybrid synthesis system, which enhance speech quality.
- API for integration on different platforms.
- The software has command-line tools.
Pros:
- Easily accessible and flexible for developers’ use in projects.
- Support all major languages.
- It is open-source thus freely available for customization.
Cons;
- Using this software requires technical knowledge.
Mozilla TTS
This is an upgraded library for advanced text-to-speech generation.
Features;
- Deep learning models which lead to high performance.
- Effective model training.
- It has a demo server for model testing.
- It comes with notebooks for detailed model benchmarking.
- Less detailed modular coding.
Pros;
- Tensorboard and console have detailed training logs.
- Supports more than 20 languages.
- It can convert PyTorch models to TRLite and Tensorflow for inference.
- Fast and efficient training.
Cons;
- None
Festival
It is a commonly used TTS software developed by the University of Edinburgh.
Features;
- Supports languages like German, English, Spanish, and French etc.
- The user can personalize voices.
- Multilingual speech generation.
- Has extensible architecture.
Pros;
- Active research and development.
- Broad range of speech customization.
- Diverse applications on numerous languages.
Cons;
- It needs substantial resources for complex projects.
Coqui TTS

Coqui TTS targets to offer accessible, top-notch and customizable TTS technology.
Features;
- Tacotron 2 and WaveGlow deep learning-based.
- Pre-trained models and resources for multiple languages.
- Speech customization.
- Community-development driven.
Pros;
- High quality speech.
- Voice diversification.
- It does not have restrictive licences.
Cons;
- It is time consuming and computational demanding.
ESPnet

This is an end-to-end speech synthesis toolkit.
Features;
- End-to-end model.
- Modular and flexible design.
- It has a broad toolkit.
Pros;
- Impeccable performance with deep learning techniques.
- Flexible research and development.
- High support by developers’ community.
Cons;
- Some users may fine the interface complicated.
Julius
Julius is a large vocabulary continuous speech recognition decoder software open for developers.
Features;
- Written on C language.
- 2-pass tree-trellis search.
- Gaussian pruning and selection.
- Enveloped beam search.
- Word-pair context approximation.
Pros;
- Compatible with all operating systems.
- High-performance.
- Word-graph output.
- It has many search parameters.
Cons;
- It calls for significant resources.
Flite

It is a simplified version of Festival TTS discussed above.
Features;
- Efficient and lightweight.
- Real-time text synthesis.
- Substantial customization options.
- Various languages and voices.
Pros;
- It is freely available for modification.
- Multilingual uses.
Cons;
- It is not suitable for complex tasks.
Tacotron
Tacotron is a deep learning based TTS created by Google.
Features;
- Deep learning architecture.
- Text filtering mechanism.
- Its output is natural and expressive.
- End-to-end synthesis.
Pros;
- High-quality speech generation.
- Efficient voice tuning and customization.
- Its architecture does not require intermediate processing steps.
Cons;
- Its training require large data volumes.
Festvox
This is an amazing TTS tool as it is rich in voice synthesis tools.
Features;
- Numerous voice customization options.
- It can be integrated with Festival TTS.
- Multilingual support.
- Voice building tools and scripts for synthetic voices.
Pros;
- It can be used for many languages.
- Festvox’s framework is flexible and extensive.
- It has synthetic voices, which can be personalized.
Cons;
- It is complex for beginners.
OpenJTalk

OpenJTalk is a Japanese language text to speech software.
Features;
- It is specially made for Japanese text to speech synthesis.
- Hidden Markov Model-based Speech Synthesis System.
- It fits with HTS voice databases.
- Command-line interface.
Pros;
- It is a free and open-source software.
- Specific to Japanese.
- Excellent modelling and architecture.
Cons;
- Command line interface might be less user-friendly.
- It is limited to Japanese.
MBROLA
This is a text-to-speech software that uses diphone.
Features;
- Compatible with various programming languages and operating systems.
- Diphone databases which are multilingual.
- Language, voice and application customization.
Pros;
- Diverse voice customization options.
- Supports up to 20 languages.
- It can be integrated easily across platforms.
Cons;
- It calls for expertise to process speech.
- Diphone has boundaries, which affect speech quality.
- Limited expressiveness.
FreeTTS

This is an open-source software developed by Sun Microsystems. It has a Java-based framework.
Features;
- Text-to-speech processing.
- Users have a wide range of voices to choose.
- The interface is programmable.
- Java-based TTS.
Pros;
- It is compatible with Java.
- The software is freely available for use and modification.
- The architecture is extensible.
Cons;
- Limited language support.
Synthesia

This is a text-to-speech software developed by Synthesia Limited. It has artificial intelligence capabilities that generate natural sounding speech from text. Synthesia can create engaging voice-overs for a good user experience.
Features;
- Allows the user to generate speech in many dialects and languages.
- Easy integration with other platforms.
- Batch and real-time synthesis.
- Wide range customization.
- Human-like speech output.
Pros;
- User-friendly interface.
- It can synthesize large text volumes.
- It generates natural sounding speech.
Cons;
- This is a premium software. Thus, you will incur subscription costs.
- It requires internet connection.
- The software is prone to inaccuracies.
- Synthesia lacks a high degree of emotional expressiveness.
Kaldi

This is an automated speech recognition software, which supports linear transforms, deep neural networks, boosted MMI, MCE and feature-space discriminative training.
Features;
- Customizable acoustic models.
- Vast and friendly support community.
- Data-driven model building.
- Building tutorials are available.
Pros;
- It comes with an array of tools.
- Kaldi is user-friendly.
- FST and Language Model creation.
Cons;
- Using it requires expertise.
- It only works with ARPA format, which jeopardizes quality.
- Automating AM building processes is difficult.
PRAAT
This is a speech manipulation and analysis toolkit. It has capabilities that can be used for text-to-speech synthesis.
Features;
- It can manipulate speech waveforms such as duration, pitch, and intensity.
- PRAAT generates simple synthetic speech.
- Scripting abilities.
- Text-to-speech scripting.
Pros;
- It has tools that can be used for TTS research projects.
- Scripting flexibility through customization.
- Speech analysis capacity.
Cons;
- It does not support many languages.
- Using it requires expertise and effort.
- Limited text-to-speech capabilities.
Voice Dream
This is a mobile text-to-speech app, which comes with a premium Acapela Heather voice.
Features;
- Library management capabilities.
- Reading modes.
- OCR.
- Audio and visual controls.
Pros;
- It has more than 200 voices and 30 languages.
- The free version has many features.
- Users can highlight text, pin notes and enjoy full-screen reading.
Cons;
- It is only available for iOS.
In a nutshell
It is paramount to consider what you need before choosing an open-source text-to-speech software. This article spells out 22 tools, which we have tried and found to be effective. Nonetheless, these software differ in features and capabilities. Select the most suitable tool for text to speech synthesis based on the provided information. Good luck in your project!