Benchmarking with Fashion MNIST Dataset using IBM FfDL

Fashion MNIST Dataset is an accurate benchmarking tool that can be trained according to what the data scientists require. Here, IBM Fabric for Deep Learning (FfDL) is used to train the Fashion MNIST model on Kubernetes Cluster.
But first, let us take a look at what exactly the Fashion MNIST dataset comprises of.
What is fashion dataset?
Fashion MNIST is an upgrade on the original MNIST dataset. It is used as a replacement due to its precision and overall better results. MNIST was based on handwritten numbers, and Fashion MNIST is based on 10 different classes of fashion accessories and clothing.
Now, let’s find out what Fabric for Deep Learning is all about.
Training with FfDL
IBM Fabric for Deep Learning, or FfDL, as it is popularly known, provides a scalable platform that is perfect for data scientists. It simplifies the process and allows data scientists to focus on the matter at hand by providing a ready stack. Fabric for Deep Learning also allows the usage of deep learning libraries, hence making it easier to interpret the data and utilize machine learning capabilities at the same time.
Essentially, IBM FfDL provides deep learning as a service, wherein data scientists can train their own models with whichever deep learning framework they prefer to use. This creates many opportunities for companies to make use of their vast amounts of collected data, wherein they can create new models and algorithms to make use of this data in a meaningful way.
Use Case
The fashion MNIST dataset was developed was use in the world of fashion. In conjunction with IBM FfDL, it can work with the deep learning capabilities to help data interpretation in a more meaningful way.
There are wide ranging applications of image classification, like in the field of healthcare, where it is used to identify diseases in medical imaging. It can also be used in online retail websites, suggesting similar products to what the customer has liked and previously purchased. Deep learning ensures that the suggestions and recommendations will only get better over increased duration of usage of the websites.
It also works well as a benchmarking tool once the model has been trained. It can also be used to check and prototype algorithms, as MNIST works well with deep learning frameworks and libraries. A linear network or convolutional neural network can be used.
Development and Process Description
In order to train a model on Fashion MNIST, a convolutional neural network (CNN) must be implemented. In this case, there are three convolutional layers, after which two dense layers are present. The process runs for 30 epochs, each made up of a batch size of 128. After the wrapping is done using Seldon, the model is now trained and will accept input.
Once the model is trained, it can then predict what class and category a particular image belongs to. One can also add labels for further information. At this point, the web app will be able to accept uploaded images, and recognize and sort them into appropriate classes, where the top three predictions are displayed on the screen, along with the uploaded image.
This is also accompanied by a word cloud made up of all the class names, where the size of the word signifies how frequently that class is a primary choice for an image.
Process Flow
Train your Fashion MNIST model with Fabric for Deep Learning (FfDL) on Kubernetes Cluster configured with GPU. This model is defined in Keras and trained using TensorFlow using Fabric for Deep Learning which is deployed on Kubernetes GPU cluster running on IBM Cloud.
On the open source side, to complete the FfDL trained model deployment story we’ve worked
together with Seldon to provide a FfDL integration.
In this code, we will show end to end example how to train, deploy, and write an application to consume to deployed model on Fashion MNIST dataset on Kubernetes.
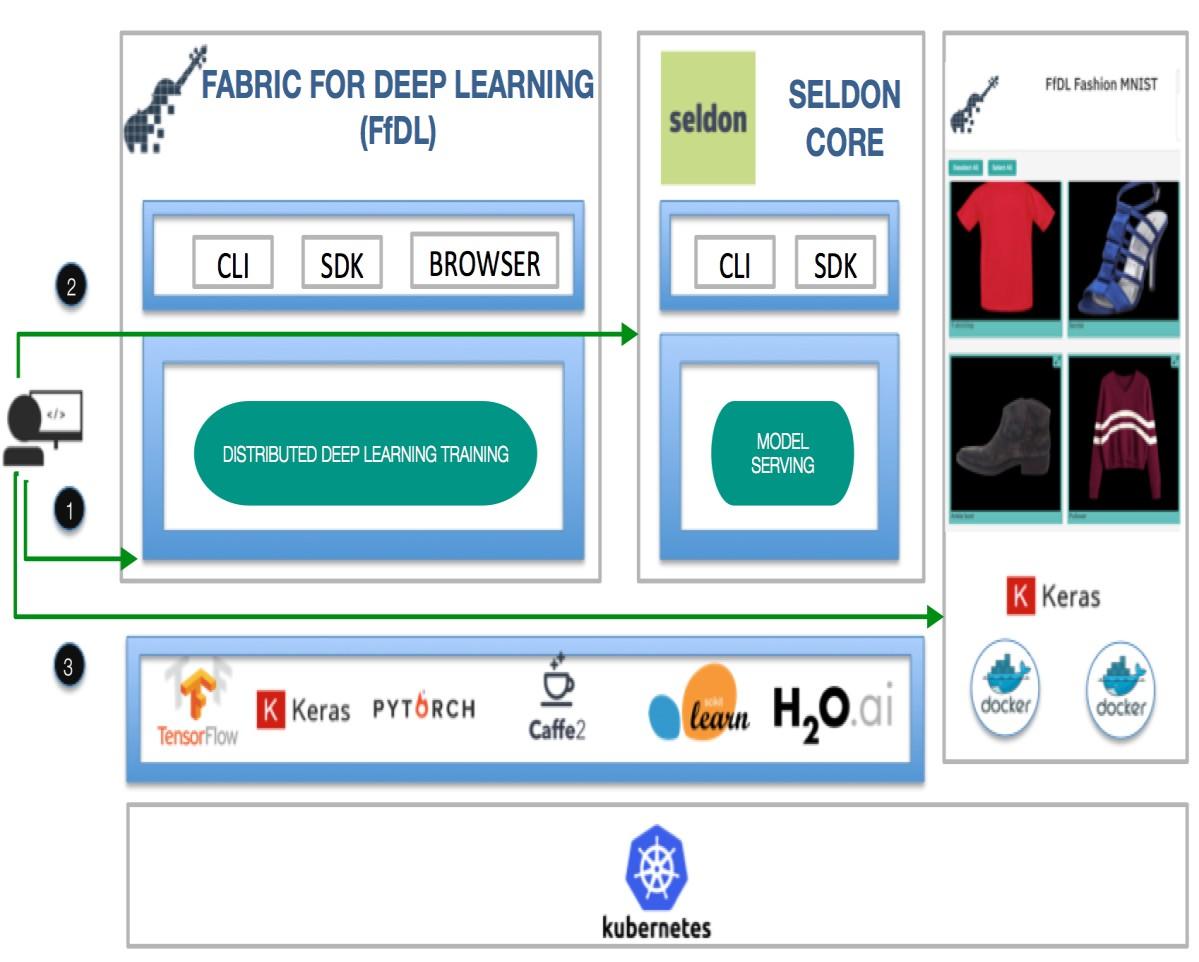
Prerequisites
You need to have Fabric for Deep Learning deployed on a Kubernetes Cluster with at least 4 CPUs and 8Gb Memory.
Steps
- Train your Fashion MNIST model with FfDL
- Deploy your Fashion MNIST model with Seldon
- Build the FfDL Fashion MNIST Web App and push it on Kubernetes
Dataset
Fashion-MNIST is a dataset provided by Zalando of clothing images. It is intended to serve as a
direct drop-in replacement for the original MNIST dataset for benchmarking ML algorithms. It shares the same image size and structure of training and testing splits, consisting of a training set of 60,000
examples and a test set of 10,000 examples. Each example is a 28×28 grayscale image, associated with a label from 10 classes.

Appropriate Test Data
The model will expect to receive a file path to a picture. Over 30 different file types are supported although only the two (.png and .jpg) have been tested extensively. These file types are listed at (http://pillow.readthedocs.io/en/5.1.x/handbook/image-file-formats.html)
The models trained on the Fashion MNIST data will work best when there is only one object in the picture and the background of the picture is pure black. Additionally, the object in the picture should be centered and completely in frame. Any image the model receives will be compressed into a 28×28 grayscaled image to match the original Fashion MNIST training set. Due to this, the model works best when the object in the picture takes up a majority of the frame.